
From ‘Computadora’ to ‘Ordenador’: The Impact of Spanish Dialects on LLM Classification Variance
Article Sidebar
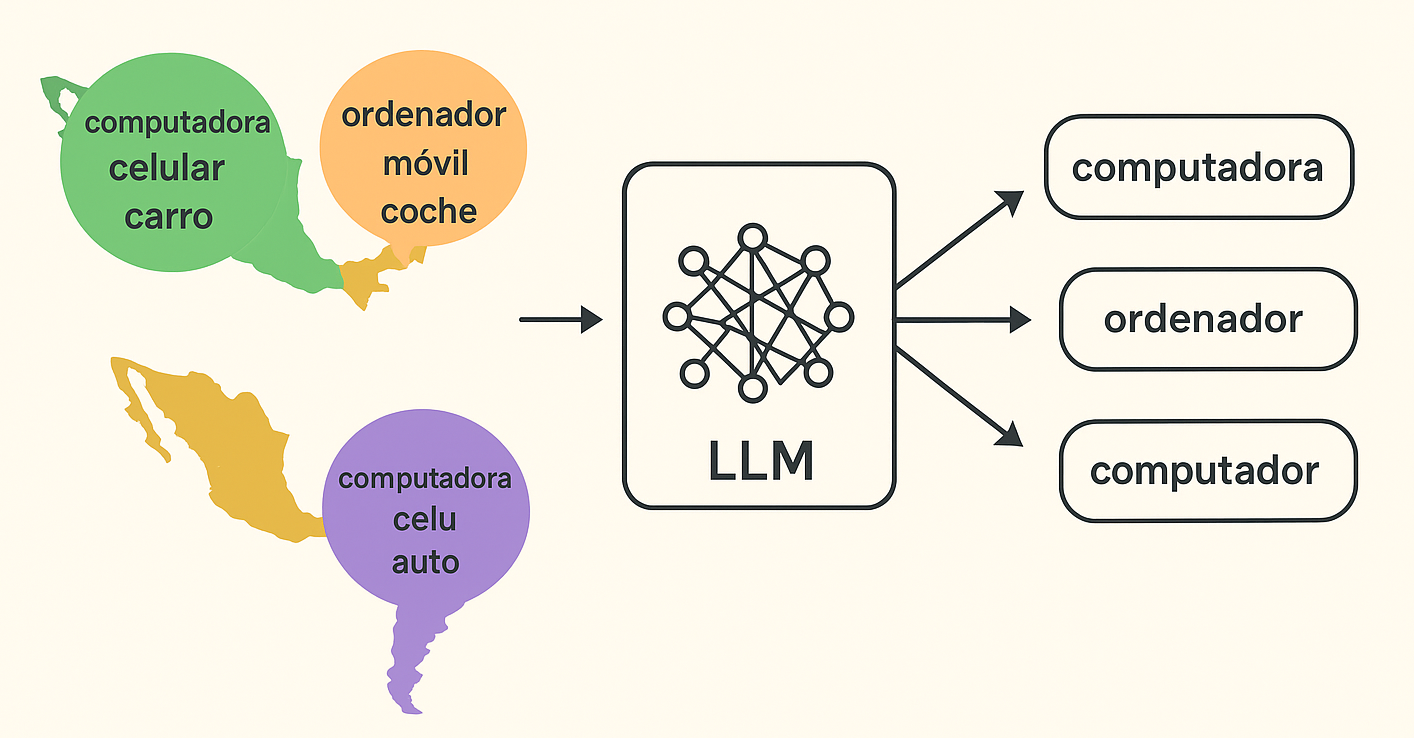
Main Article Content
Abstract
This study investigates the impact of Spanish dialectal variation on the performance and reproducibility of Large Language Models (LLMs) in text classification tasks. Specifically, it compares Peninsular Spanish and Mexican Spanish using benchmark datasets for sentiment analysis and fake news detection. The methodology follows the CRISP-DM framework, emphasizing data normalization, dialectal adaptation, and controlled model evaluation through multiple training runs. Models such as RoBERTa were fine-tuned and tested to quantify both intra-model and inter-dialectal variance. Results show that models trained on Peninsular Spanish achieved higher stability and accuracy in sentiment analysis, while those trained on Mexican Spanish performed better in fake news detection. These differences reveal that dialectal variation significantly influences model behavior and highlight the limitations of relying solely on one Spanish variant for NLP tasks. The findings underscore the importance of developing balanced and representative datasets that capture the linguistic diversity of Spanish, ultimately contributing to fairer and more reliable LLMs for multilingual applications.
Article Details
References
Aguaded, I., Pilo, M. A., Romero, J. M., & de-Casas, P. (2024). El impacto de la inteligencia artificial en comunicación: Revisión sistematizada de la producción científica española en Scopus (2020–2023). Revista Publicaciones, 28(119), 65–79. https://doi.org/10.26807/rp.v28i119.2098
Amaratunga, T. (2023). Understanding large language models: Learning their underlying concepts and technologies. Apress. https://doi.org/10.1007/979-8-8688-0017-7
Bourriot, S., Garnier, C., & Doublier, J. L. (1999). Phase separation, rheology and microstructure of micellar casein–guar gum mixtures. Food Hydrocolloids, 7, 90–95. https://doi.org/10.1016/S0268-005X(98)00068-X
Company Company, C. (2019). Jerarquías dialectales y conflictos entre teoría y práctica: Perspectivas desde la Asociación de Academias de la Lengua Española (ASALE). Journal of Spanish Language Teaching, 6(2), 96–105. https://doi.org/10.1080/23247797.2019.1668179
Faisal, F., Ahia, O., Srivastava, A., Ahuja, K., Chiang, D., Tsvetkov, Y., & Anastasopoulos, A. (2024). DIALECTBENCH: A benchmark for dialects, varieties, and closely-related languages. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 14004–14027).
Kong, Y., Nie, Y., Dong, X., Mulvey, J. M., Poor, H. V., Wen, Q., & Zohren, S. (2024). Large language models for financial and investment management: Applications and benchmarks. The Journal of Portfolio Management: Quantitative Tools, 51(2), 162–210. https://doi.org/10.3905/jpm.2024.1.645
Lazo, V. R. (2022). Clasificación de la personalidad utilizando procesamiento de lenguaje natural y aprendizaje profundo para detectar patrones de notas de suicidio en redes sociales (Tesis de licenciatura). Universidad Católica San Pablo, Arequipa. https://renati.sunedu.gob.pe/handle/sunedu/3359968
Merchán, E. L. (2024). Aplicación de modelos Transformers para clasificar textos en idioma español (Tesis de pregrado). Universidad Estatal Península de Santa Elena (UPSE). Repositorio Institucional UPSE.
Portal Administración Electrónica. (2024, 27 de febrero). El Gobierno anuncia la construcción de un modelo de lenguaje de IA entrenado en español y las lenguas cooficiales. https://administracionelectronica.gob.es/pae_Home/pae_Actualidad/pae
Schröer, C. (2021). A systematic literature review on applying CRISP-DM. Procedia Computer Science, 526–534. https://doi.org/10.1016/j.procs.2021.01.199
Sierra, G., Montaño, C., Bel-Enguix, G., Córdova, D., & Mota, M. (2020). CPLM, a parallel corpus for Mexican languages: Development and interface. In Proceedings of the Twelfth Language Resources and Evaluation Conference (pp. 2947–2952). European Language Resources Association.
Udacity. (2025). CRISP-DM explained: A proven data mining methodology. Udacity Blog. https://www.kdnuggets.com/2014/10/crisp-dm-top-methodology-analytics-data-mining-data-science-projects.html
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. arXiv. https://doi.org/10.48550/arXiv.1706.03762
Xue, Y., Cao, X., Yang, X., Wang, Y., Wang, R., & Li, J. (2023). We need to talk about reproducibility in NLP model comparison. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 9544–9557). Association for Computational Linguistics.